This is a quick walk-through tutorial of Java Map interfaces and their implementations.
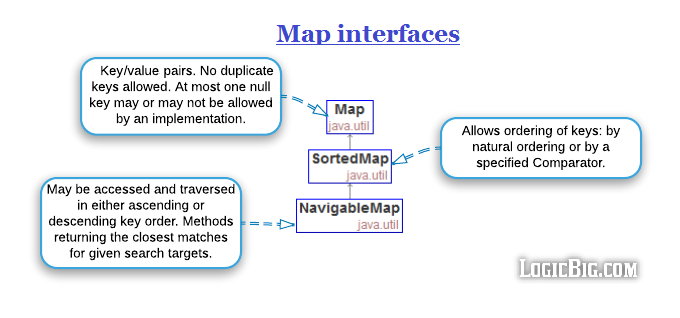
Interfaces
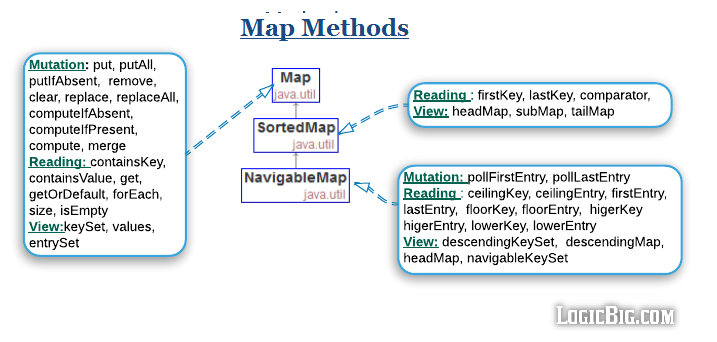
Methods
Implemetations
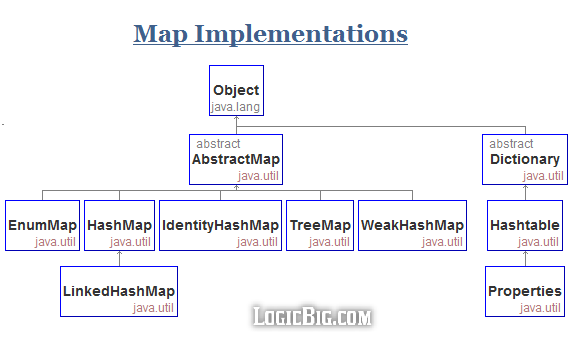
Impl |
ADT |
Data Structure |
Performance (Big O notation) |
EnumMap
(sync)
Keys = A single enum type elements,
Values = any object. |
Map |
Fixed size Array of 'value' objects initialized to full size of underlying enum elements. The indexes of the 'value' array are the enum ordinals.
Null keys are not permitted.
Maintained in the natural order of their keys (per ordinals, the order in which the enum constants are declared) |
All methods O(1). Likely (though not guaranteed) to be faster than their HashMap counterparts.
Iterators returned by the collection views are weakly consistent. |
HashMap
(sync) |
Map
|
Hash table: maintains an array of buckets. Each bucket contains one or more key/value pairs. One particular key's hash (retrieved using hashCode() method of the key object) is masked to the buckets array index. Since multiple keys are allowed to have same hash (hash collisions), each bucket's element maintains a linked data structure (having references of other key/value pairs). After matching hash code, the particular match within a bucket linked structure is searched using key's equal() method, that also means if two keys have same hash per hashCode() method then they should not be same per equal() method.
Permits at most one null key.
capacity : no of buckets (default 16)
Load Factor : rehash factor (default 0.75f i.e 75% of map size). When (capacity * load factor) >= (size of the map), then bucket array size is doubled (an expensive process). e.g. default 16 * 0.75 = 12 means when storing the 12th key/value pair into the map , its capacity becomes 32. |
get, put: O(1)
It can be O(n) if we use bad hashCode causing more elements added to one bucket.
Iteration over collection views requires time proportional to the capacity of the map plus its size. Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
Java 8 Optimization: Under high hash-collision conditions O(log n). Balanced trees are used internally rather than linked lists to store map entries. |
Hashtable
(sync)
(Legacy) |
Map
|
Hash table: Similar to HashMap but is thread-safe.
null is not permitted for keys or values. |
Same as HashMap ignoring synchronization overhead.
No Java 8 tree nodes optimization. |
LinkedHashMap
(sync)
|
Map |
Hash table + Doubly-linked list.
Insertion-order of the keys is maintained.
Insertion order is not affected if a key is re-inserted.
Permits at most one null key. |
get, put: O(1) (Similar to HashMap)
It can be O(n) if we use bad hashCode causing more elements added to one bucket.
Performance is likely to be just slightly below that of HashMap, due to additional maintenance of the linked keys, with one exception: Iteration over the collection-views of a LinkedHashMap requires time proportional to the size of the map, regardless of its capacity. Iteration over a HashMap is likely to be more expensive, requiring time proportional to its capacity.
|
IdentityHashMap
(sync) |
Map |
Hash table.
A special Map where all methods use == for comparing keys instead of equals() method.
Should be used whenever each key has a single global instance (memory reference) e.g when using java.lang.Class, strings returned by String.intern() or proxy objects.
Permits at most one null key.
No need to override equal() and hashCode() methods for key object.
System.identityHashCode(Object) is used for bucket allocations.
Expected Max Size is the only tuning parameter (user cannot specify capacity or load factor). Internally, this parameter is used to determine the number of buckets. If size of the map exceeds beyond maximum size, the number of buckets are increased (rehashing, an expensive process). |
get, put: O(1)
It can be O(n) if System.identityHashCode(Object) doesn't disperse elements properly among buckets or maximum limit is crossed.
Iteration over collection views requires time proportional to the number of buckets in the hash table, so it pays not to set the expected maximum size too high if we are especially concerned with iteration performance or memory usage.
It uses simple linear probing, rather than separate linked-list chaining, hence the performance is better than HashMap. |
WeakHashMap
(sync) |
Map |
Hash table.
Weak keys: An entry in this map will automatically be removed when its key is no longer in ordinary use. That is, it will not be prevented from being garbage collected. Because the garbage collector may discard keys at any time, a WeakHashMap may behave as though an unknown thread is silently removing entries.
Permits at most one null key.
Initial capacity and load factor are the tuning parameters (just like HashMap) |
This class has performance characteristics similar to those of the HashMap class. |
TreeMap
(sync) |
NavigableMap |
Red-black tree.
Null keys are not permitted. |
containsKey, get, put, remove: O(log n)
Iteration over collection views: O(log n)
|
Choosing a Map
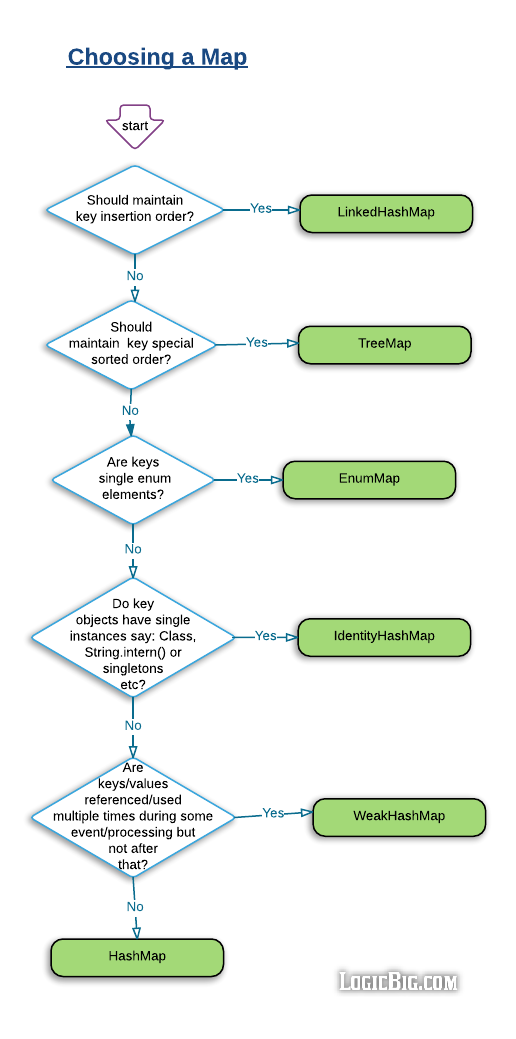
Synchronization
java.util.Collections provides methods to wrap any map around a new map which is synchronized. These methods are:
Map<K,V> synchronizedMap(Map<K,V> m)
Map<K,V> synchronizedSortedMap(SortedMap<K,V> m)
Map<K,V> synchronizedNavigableMap(NavigableMap<K,V> m)
Note: It's not recommended to use legacy Hashtable.
Read Only Maps
The util class java.util.Collections also provides methods that return an unmodifiable view of the specified map. These methods allow to provide client code with "read-only" access to internal maps. Query operations on the returned map "read through" to the specified map, and attempts to modify the returned map, whether direct or via its collection views, result in an UnsupportedOperationException. Those methods are:
Map<K,V> unmodifiableMap(Map<? extends K,? extends V> m)
SortedMap<K,V> unmodifiableSortedMap(SortedMap<? extends K,? extends V> m)
NavigableMap<K,V> unmodifiableNavigableMap(NavigableMap<K,? extends V> m)
|
|
